原文链接 https://www.dolthub.com/blog/2025-06-20-go-pprof-diffing/
我们正在努力进行兼容性工作 Doltgres,世界上首个且唯一的版本控制兼容 Postgres 的 SQL 数据库。这意味着它能够开箱即用地与 Postgres 兼容的每一款库和工具协同工作。近来我们投入了大量精力在 SQLAlchemy 上,这是一款流行的 Python ORM。他们的 MySQL 集成与 Dolt 配合完美无缺,但他们的 Postgres 版本显然完全不同,严重依赖 pg_catalog 表。一位客户尝试使用后发现存在许多空白 ,因为 Doltgres 未将系统表(例如 dolt_log)包含在 pg_catalog 表中。所以我修复了这个问题,但这导致我们其中一个测试套件出现了神秘的性能退化,速度慢了 3 倍。
费了相当大的心思才弄清楚为什么这样一个看似无害的更改会导致性能出现如此巨大的差异。最终,最有帮助的是一个令人惊叹的 Go 工具链工具:使用 -base 选项来可视化两个性能分析之间的差异。 pprof
使用 pprof 对两个 profile 进行差异比较
Go 自带了一个强大的性能分析工具,pprof。与某些其他语言不同,您必须在代码中显式启用它才能获取性能分析结果;您不能事后进行或使用命令行标志。这很简单,但您必须编写代码来实现它。在我们的案例中,我将它直接放置在被分析的性能测试方法中。
func TestRegressionTests(t *testing.T) {
// We'll only run this on GitHub Actions, so set this environment variable to run locally
if _, ok := os.LookupEnv("REGRESSION_TESTING"); !ok {
// t.Skip()
}
p := profile.Start(profile.CPUProfile)
defer p.Stop()
这段代码的最后两行启动了一个 CPU 分析文件,然后在方法完成时停止它。它使用了 github.com/pkg/profile 包,该包提供了更便捷的内置分析器库封装。如果你运行这段代码,你会看到类似以下输出的行:
2025/06/20 14:10:40.548730 profile: cpu profiling disabled, C:\Users\ZACHMU~1\AppData\Local\Temp\profile1113350212\cpu.pprof
这是运行生成的配置文件的位置,您应该将其记下或复制到另一个更容易记住的位置。
为了我的测试,我想看看在 main 分支和我当前分支上的性能变化,因此我在每个分支上启用了分析功能的测试。现在我可以使用 -base 标志和 pprof 来比较它们。
检查性能差异
在为每个分支获取了分析文件后,我现在只需要比较它们。
go tool pprof -http=:8090 -base main.pprof branch.pprof
-base 标志告诉 pprof 在报告性能数据时将命名配置文件从另一个配置文件中"减去"。在这种情况下,我想看看 branch.pprof 中发生了什么,但不包括 正在处理 main.pprof,这太耗时了。我还一直使用 -http 标志,它运行一个交互式网络服务器而不是命令行界面。在调查性能配置文件时,我发现这样使用起来要容易得多。
当我运行该命令时,我的网络浏览器启动到默认显示器,显示了一个按函数大致拓扑排序的累积 CPU 样本图,这样你就能看到哪些函数调用哪些函数。与普通的性能分析不同,这里显示的数字严格是两个配置文件之间的差异,而不是它们的绝对运行时间。以下是我在我网络视图中看到的内容:
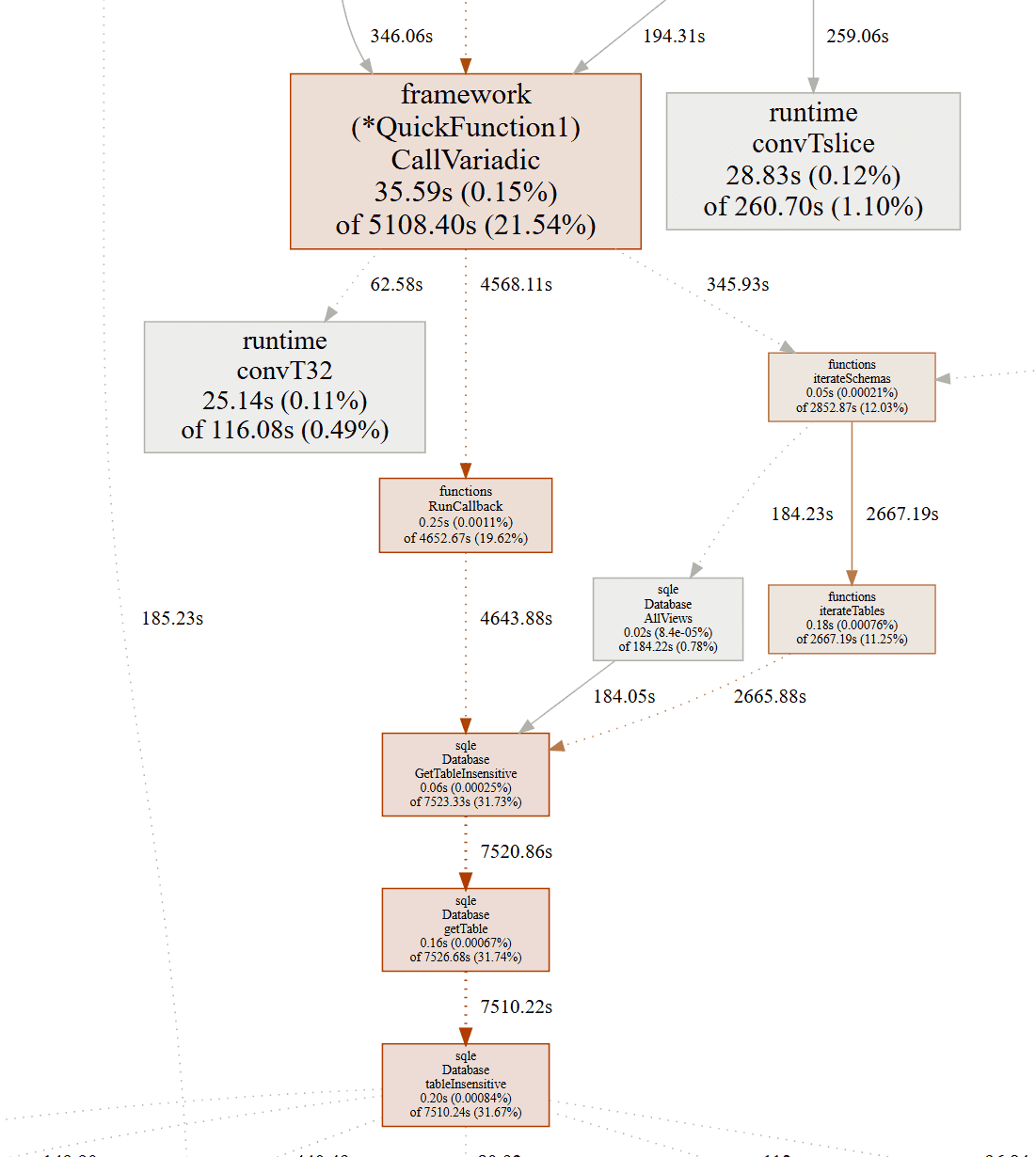
Database.tableInsensitive 是用于获取查询引擎使用的表对象的函数。不知何故,我的更改使这个函数变得非常非常慢,尽管我没有直接编辑它。有了这个线索,我能够找到性能问题。
// from tableInsensitive()
...
tableNames, err := db.getAllTableNames(ctx, root, true)
if err != nil {
return doltdb.TableName{}, nil, false, err
}
if root.TableListHash() != 0 {
tableMap := make(map[string]string)
for _, table := range tableNames {
tableMap[strings.ToLower(table)] = table
}
dbState.SessionCache().CacheTableNameMap(root.TableListHash(), tableMap)
}
tableName, ok = sql.GetTableNameInsensitive(tableName, tableNames)
if !ok {
return doltdb.TableName{}, nil, false, nil
}
代码片段的第一行如果会话中尚未缓存表名,则从数据库中加载所有表名。这是必要的,因为我们的表名以大小写敏感的方式存储,但 SQL 是大小写不敏感的。因此,在从数据库加载表时,我们需要将查询中的大小写不敏感名称更正为大小写敏感的名称,以便在存储和 I/O 层中使用。但是,对 db.getAllTableNames() 的调用包括一个最终参数: includeGeneratedSystemTables。这个参数被硬编码为 true,这意味着它总是调用获取生成系统表列表的新、更昂贵的方法,这包括潜在的磁盘访问以获取数据库模式集,然后对它们进行大量迭代。
schemas, err := root.GetDatabaseSchemas(ctx)
if err != nil {
return nil, err
}
// For dolt there are no stored schemas, search the default (empty string) schema
if len(schemas) == 0 {
schemas = append(schemas, schema.DatabaseSchema{Name: doltdb.DefaultSchemaName})
}
for _, schema := range schemas {
tableNames, err := root.GetTableNames(ctx, schema.Name)
if err != nil {
return nil, err
}
for _, pre := range doltdb.GeneratedSystemTablePrefixes {
for _, tableName := range tableNames {
s.Add(doltdb.TableName{
Name: pre + tableName,
Schema: schema.Name,
})
}
}
// For doltgres, we also support the legacy dolt_ table names, addressable in any user schema
if UseSearchPath && schema.Name != "pg_catalog" && schema.Name != doltdb.DoltNamespace {
for _, name := range doltdb.DoltGeneratedTableNames {
s.Add(doltdb.TableName{
Name: name,
Schema: schema.Name,
})
}
}
}
结果证明,硬编码的 true 是错误的——这个方法根本不需要考虑系统生成的表名。但在我将生成这些名称的过程变得更昂贵之前,这是一个相对无害的错误,而且已经在代码中存在多年而未被注意到。将此值更改为 false 以移除不必要的操作解决了性能回归问题,同时也略微提高了 Dolt 的基准测试速度。
| read_tests | from_latency | to_latency | percent_change |
|---|---|---|---|
| covering_index_scan | 0.68 | 0.67 | -1.4 |
| groupby_scan | 19.65 | 19.29 | -1.83 |
| index_join | 2.57 | 2.52 | -1.95 |
| index_join_scan | 1.44 | 1.44 | 0.0 |
| index_scan | 30.26 | 29.72 | -1.78 |
| oltp_point_select | 0.29 | 0.28 | -3.45 |
| oltp_read_only | 5.37 | 5.28 | -1.68 |
| select_random_points | 0.61 | 0.6 | -1.64 |
| select_random_ranges | 0.64 | 0.62 | -3.13 |
| table_scan | 32.53 | 31.94 | -1.81 |
| types_table_scan | 127.81 | 125.52 | -1.79 |
如果没有 -base 标志指引方向,我可能永远也找不到这个低效问题的根源。
结论
关于 Go 性能分析或 Doltgres 的问题?欢迎来我们这里 Discord 与我们的工程团队交流,并结识其他 Doltgres 用户。